DSAR Overview
Due to an increasing awareness for privacy, regulators have been led to introduce new Data Privacy and Data Protection requirements in order to protect consumer, health, financial and other sensitive information.
In recent years as data has become digitized, more prevalent, and more accessible, these laws and regulations are stricter and are being passed more frequently. These laws are passed with the objective of giving control back to individuals over their personal data. However, the Privacy Regulation landscape is becoming more and more complex and compliance is becoming more and more of a challenge.
Recent regulations require organizations to identify and detect personal identifiable information (PII) such as Name, Aliases, Addresses / Locations, SSNs, IDs, email addresses, account numbers, etc. Organizations need be able to respond and disclose all occurrence of a person’s PII data upon request.
These requests, often referred to as the Right-of-Access and the Right-to-be-Forgotten, are handled by processes called Data Subject Access Requests (DSARs). Also known as a “subject rights request” or a “privacy rights request,” a DSAR is a submission by an individual (or data subject) to a business asking to know what personal information of theirs has been collected and stored, as well as how it’s being used.
Individuals can also use a DSAR to ask organizations to take certain actions with their data, such as deleting it, correcting incorrect data, or opting out of future data collection. Enterprises worldwide are faced with the task of responding to these and thousands of similar privacy requests annually – all of which must be completed within strict time frames. Yet, the current processes to do so are both time-consuming and complicated.
There are several clear and distinct steps that most DSARs go through. The biggest hurdle for organizations is the data discovery process – locating individual identity information within huge volumes of unstructured data. Another key challenge is coordinating within the organization between the different stakeholders that need to be involved in correlating, validating and remediating the detected information. Verifying that the remediation was successful and orchestrating and managing compliant responses to requesters and auditors are other tasks that need to be completed. This is especially difficult, as current processes used to identify, correlate, and remediate the data, as well as manage compliance responses, are prone to errors, and aren’t scalable.
File Access Manager Privacy Engine includes the DSAR Campaign Workflows capability. Automated DSAR campaign workflows leverage AI-Driven NLP-based data discovery and orchestrates data validation, remediation and verification reviews, to address complex compliance requirements, enable quick collaboration, and considerably cut processing time – enabling organizations to scan, identify, report on and collaborate over the remediation of Personally Identifiable Information.
DSAR Workflow
Processing DSARs (Data Subject Access Requests) involves several stages:
- Submitting the request – An individual submits a request for information to be disclosed, removed, or edited.
- Validating the identity – The organization receiving the request must validate the requester's identity to ensure the request is valid and that the information is disclosed only to the individual or an authorized proxy.
- Discovering the data – Typically the longest stage. All PII (Personally Identifiable Information) associated with the individual across all organizational data sources is identified.
- Validating the data – Once all PII is discovered, the data needs to be validated to ensure it relates to the data subject.
- Remediating the data – If the requester asked for data to be redacted, updated, or removed, this stage will address those requests.
- Verifying – Once remediation is complete, ensure the data detected was modified or removed.
- Responding – As part of the DSAR response, all data about the individual and the processing it went through is reported, packaged, and securely delivered to the requester.
File Access Manager DSAR Campaign Workflows
File Access Manager DSAR campaign workflows address the Data Discovery, Validation, Remediation, and Verification stages. Once data is discovered by the privacy engine, each campaign workflow consists of the following phases:
Phase One – Data Validation
In this phase, the reviewer is presented with the results based on the campaign DSAR query and scope. The reviewer must review the identified files and decide whether they should be included in the DSAR processing or excluded from further processing (e.g., due to a file being detected by mistake).
- All decisions made must be committed to complete the review level.
- The review process can involve multiple reviewers at each stage, but a decision on each file can only be made by a single reviewer.
- When all results have been confirmed or excluded and committed, the campaign will transition to the Data Remediation phase. The campaign status will change to "Data Remediation in Progress" (this status may take a few moments to update).
Note
Information Disclosure DSAR Campaigns do not include a Data Remediation phase. See the DSAR Campaign Purposes section for more information.
Phase Two – Data Remediation
In the Data Remediation phase, all files confirmed for further processing are included. Reviewers will collaborate and report the completion of remediation tasks, such as redacting or removing PII data, or excluding files from remediation due to compliance issues.
- After files have been reviewed and acted on, the reviewer must either:
- Mark the files that have been acted on as Done.
- Mark data that cannot be acted on as Excluded.
- Once all files are marked as Excluded or Done and everything has been committed, the DSAR campaign status will change to Data Remediation – Completed (this status may take a few moments to update).
Note
The status of the campaign may take a few moments to be updated.
Phase Three – Data Verification
The purpose of the Data Verification phase is to verify that the remediation actions were performed correctly and that all detected information has been addressed (whether it was removed, redacted, or changed).
Once verification is initiated:
- A task will be created. Wait until it is finished (this can take a while).
- The campaign status will change to Verification in Progress.
- When the task is finished, the campaign status will change to Verification is Done.
Note
If the verification task fails, the campaign status will change to Verification Failed.
To view the campaign verification results, navigate to Compliance > DSAR Management > DSAR Campaign Details.
Verification Statuses:
- Failed: If the requested campaign query yields results on a file, it will be marked as Failed.
- Verified: If the requested campaign does not yield results on a file, it will be marked as Verified.
- Verified with Exceptions: If the requested campaign yields results but with exceptions, it will be marked as Verified with Exceptions.
- Unable to Verify: If the file is not accessible or does not exist, it will be marked as Unable to Verify.
In this phase, the administrator or compliance manager can decide to:
- Override a failed campaign.
- Reassign it to another reviewer.
- Force it back into the remediation phase.
Supported Applications
Data Classification supports the following applications:
- Azure Files
- Box
- Ctera
- DFS for CIFS
- Dropbox
- EMC Celerra/VNX/Unity for CIFS
- EMC Celerra/VNX for NFS
- EMC Isilon for CIFS
- Generic CIFS
- Google Drive
- Hitachi HNAS
- Microsoft OneDrive for Business
- Microsoft SharePoint Online (Office 365)
- Microsoft SharePoint
- Microsoft Windows
- NetApp for CIFS
- NetApp for NFS
- NFS v3/v4
Supported File Types
The privacy engine indexes data based on a file’s content and attributes. The system also supports file properties and custom properties for all supported file types. The privacy engine reads file content based on the file extension.
Image files can be analyzed and searched for keywords using an Optical Character Recognition (OCR) capability. This is a resource-heavy process and is configured separately. See section Optical Character Recognition (OCR).
The Data Classification engine supports the following file types/extensions:
| File Extension | Expected file type |
|---|---|
| docx doc xls xlsx ppt pptx | Microsoft Office files |
| txt csv | Plain Text (including Comma Separated Values files) |
| htm html xml | Web files |
| cs js sql | Code script files |
| zip gzip tar rar 7zip | Archive files |
| Jpeg jpg tif tiff gif png wmf emf bmp pdf | Image files analyzed by the OCR module* |
The system downloads files from cloud-based content stores and non-CIFS application (for example, Box, DropBox, Google Drive, OneDrive, SharePoint and NFS) to a local directory on the server. Once the indexing process finishes, the system deletes the downloaded files from the indexing server.
Optical Character Recognition (OCR)
File Access Manager can identify text from within image files either directly or embedded in other files, such as scanned documents or a collection of scans stored in a zip file. Files less than 1000 pixels across will not be scanned to avoid less reliable results from low-resolution images.
The data privacy engine can analyze files containing sensitive data in image form.
Note
The optical character recognition process is resource-intensive and should be configured carefully, taking the run-time into consideration. It is disabled by default.
OCR capability can be added to the scope selected in the DSAR Scope screen.
Enabling Optical Character Recognition
By default, optical character recognition is disabled on the entire scope of the DSAR. To enable optical character recognition on a resource, edit the application scope line.
- Find the desired application from the DSAR Scope screen.
- Select Edit.
- Select Optical Character Recognition (OCR) to enable OCR analysis for this application.
Privacy PII Detection Architecture and Flow
The File Access Management Data Privacy feature is powered by SpaCy, an open-source library for advanced natural language processing (NLP) textual analysis. Using the SpaCy AI model, File Access Management can detect names and addresses through contextual analysis of the scanned documents' contents.
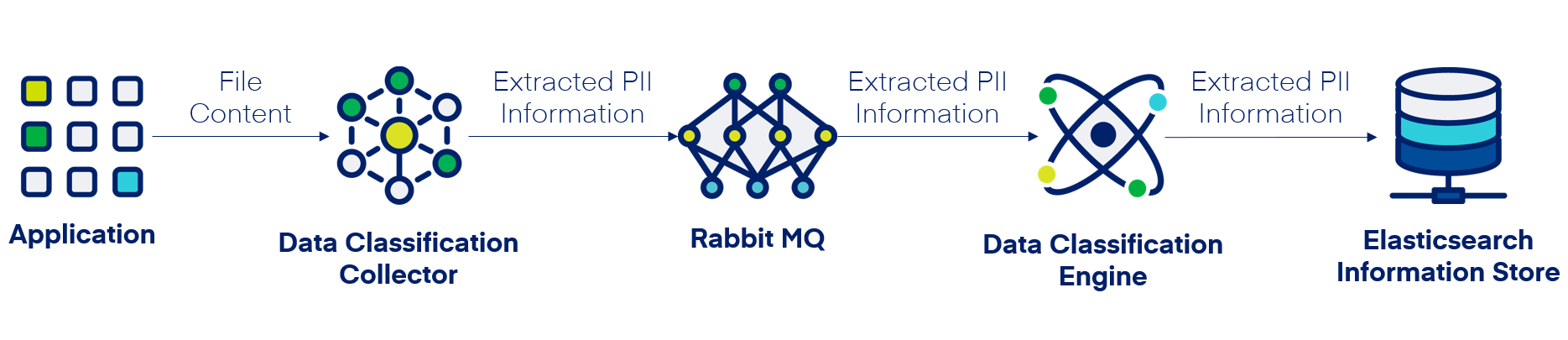
Text PII Detection
File Access Management uses various tools to detect PII (Personally Identifiable Information):
-
Name and Address – Using the SpaCy NER (Named Entity Recognition) module with the SailPoint custom trained model, File Access Management can detect both names and addresses.
-
Identifications (Social Security Numbers, Employee ID Numbers, etc.) – File Access Management uses regular expressions to identify IDs.
-
Emails – File Access Management uses SpaCy’s built-in email regular expression pattern to detect email addresses.
-
Phone Numbers – File Access Management uses SpaCy’s pattern matching feature to detect phone numbers based on predefined formats. The Privacy PII detection engine will attempt to match both local and international phone number patterns if they comply with the standard format of the relevant country.
| Supported Formats | Unsupported Formats |
|---|---|
| +1.253.215.8782 | 1300030886 |
| (212) 465-6471 | 22.4389483 |
| (212) 465-6471 |
PII Search and Relevancy Scoring
The File Access Manager Privacy Engine will search for all submitted PII search criteria.
Search criteria marked as "Required" will be mandatory. If a file does not match these criteria, it will not be returned as a result.
Search criteria that are not marked as "Required" will not exclude a file if not matched, but will contribute to the overall relevancy score.
Relevancy Score
A document relevancy score signifies the accuracy percentage between the document content and the search criteria. The higher the relevancy score, the higher the probability the information matched belongs to the individual whose details we've entered in the search criteria. The more elaborate and well-defined the search criteria is, the better accuracy the privacy engine can produce. For example, searching for just a first name or a nickname is likely to return a large number of false positive, since there are likely to be many matches of that name.
However, searching for a specific email, name, and ID is likely to produce much more accurate results.
The relevancy score is calculated based on the number of search criteria and the accuracy of the data the privacy engine was able to match. Each search criteria has a relative relevancy score allocation that contributes to the overall relevancy score.
For example, when you perform a search using four search criteria, each criterion has a weight of 25% of the overall score, or a relative score accounting for 25% of the overall score.
The overall score will be based on the number of criteria matched. If the search matched only one out of four search criteria, the overall relevancy score would be 25%.
If two search criteria were matched, the relevancy score would be 50%, and so forth. A full match of all search criteria would yield a 100% relevancy score match.
Name fields offer more granular relevancy scoring. If a name search criteria is matched in its entirety, then it will contribute the full amount of its relative relevancy score. However, Name fields (the Name and Alias fields) are also evaluated for partial matching. In case a name search criteria was partially matched, it will contribute only 50% of it's relative relevancy score to the overall score.
For example, with a four-term search criteria, when one of the search criterion is the name "John Smith," the name field will have a 25% relative relevancy score.
If the name is matched fully, that is, the name "John Smith" in matched fully in the document, the name search criteria will contribute the full 25% to the overall relevancy score.
However, if the name is partially matched, for example, the file contains "John" or "Smith," only half of the relative relevancy score would be accounted for in the document overall relevancy score. Thus, the more search criteria involved in the DSAR query, the less impact partial matching have on the overall score, since the likelihood that the identity search for was actually matched is much higher.
So, in the previous example, if we're looking for 4 data points (e.g., ID, Address, Email and Name ) – the search matched the first three and fully matched the name – the relevancy score would be 100%.
However, if the first three criteria are matched and the name is matched partially, the relevancy score would be 87%. It is still high, since we hit 4 different data points and there's a high probability the document matched the identity, or individual we're searching for, even if the name was not fully matched. However, if the query is searching just for a name, and the name is partially matched, then the overall score would be 50%, as opposed to a 100% for a fully matched name.
Lower probability documents are documents with a low relevancy score. They can easily be excluded from further DSAR processing. The decision to exclude files from further DSAR processing is with the discretion of Privacy Manager and Reviewers.