Classification Types
Regular Expressions Within Policy Objects
Regular expressions form the basis for many content pattern searches. File Access Manager uses the .net regular expression engine as its underlying engine for regular expressions searches. All regular-expression definitions and searches must conform to the engine’s restrictions, limitations, and standards.
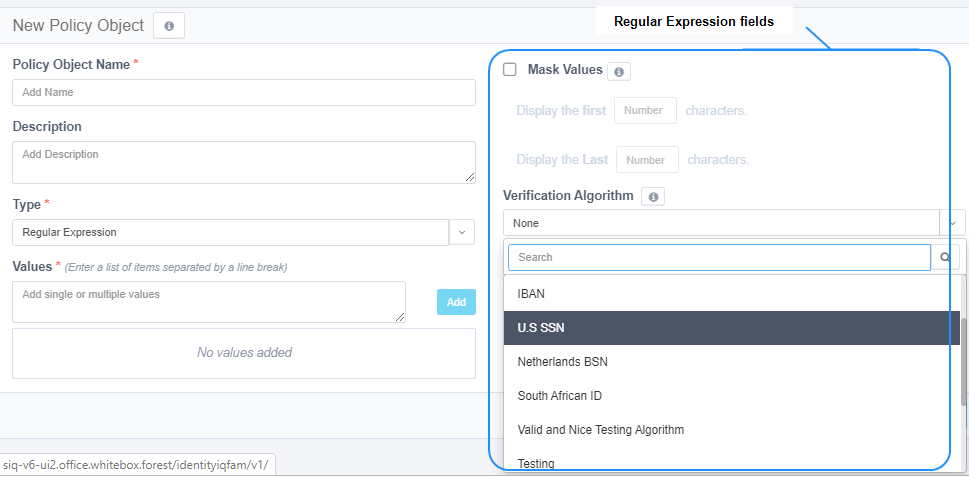
When selecting a policy of type Regular Expression, the New Policy Object panel adds the following fields to the New Policy Object panel (see image above).
Verification Algorithm
A standard, out of the box example, is the Luhn verification algorithm. This algorithm ensures that all phrases classified as credit cards are, indeed, valid credit card numbers (as far as an algorithm can validate without contacting the bank, of course). When selected, this verification will only be run on strings that conform with the credit card regular expression entered, for example:
“^3[47][0-9]{13}$”
See Data Classification Verification Algorithms for a full description on creating verification algorithms.
Mask Values
By default, the regular-expression matches are saved as part of the results. It is recommended to mask the values of the matches to avoid exposing sensitive data in the File Access Manager database.
![]()
Regex Matching and Case
Please note that regex matching is case sensitive by default. To make a regex ignore case, use the prefix “(?!)”
For example: “home” will find “home”, but ignore “Home”
The regex “(?!)home” will find “Home”, “HOME” and “HoMe”
Identifying Line Breaks using Regex in File Access Manager
For parsed files, line breaks are represented by a single CR (\r), instead of (\r\n) or (\n), and therefore not identified by the regex line boundaries ^ and $.
if we take the following regex:
(?m)(^|\s)up($|\s)
And try to match it with the following text (assuming the line breaks are \r):
going
up
up
and away!
It will not match anything since the line breaks are not \n as expected by the regex.
In order to identify the start and end of a line, we have to check for the CR explicitly. The issue is that once we identify an end of line character, the cursor has moved past this character, and we can't use this to identify the start of the next line.
If we change the regex to look like this:
(\r|\s)up(\r|\s)
It’s going to match only the first up, since the \r character will be part of the match and thus not part of the evaluation for the next “up.”
We need to check the previous and next characters, without moving the cursor.
If we try the following regex:
(?<=(\r|\s))up(?=\r|\s)
Both “up” strings will be matched. This is because of two modifications:
(?<=...) positive lookbehind,
When there’s a match, it moves back to assert whether the regex that replaces “...“ is matched, but then discards the match and moves forward to where it was to continue matching.
(?=...) positive lookahead
When there’s a match, it moves forward to assert whether the regex that replaces “...“ is matched, but then discards the match and moves back to where it was to continue matching.
Combining those two means the match contains only “up” without the preceding or following \r, so they can be used for more matches.
These non-capturing matches are known as zero-length assertions. For more information on lookahead and lookbehind assertions (collectively called lookaround) see https://www.regular-expressions.info/lookaround.html.
Examples
To look for rows starting with "John," you could use: (?<=\r|^)John.*(?=\r|$)
To look for rows ending in "Doe," you could use: (?<=\r|^).*Doe(?=\r|$)